

مدل هوش مصنوعی چیست؟
مدل هوش مصنوعی (AI Model) برنامهای است که با استفاده از دادههای آموزشی، توانایی تشخیص الگوها، پیشبینی نتایج یا تصمیمگیری مستقل را بدون نیاز به دخالت انسان دارد. این مدل در واقع قلب تپنده فناوری هوش مصنوعی است که با بهرهگیری از الگوریتمهای مختلف، دادههای ورودی را پردازش کرده و خروجیهایی متناسب با هدف برنامهریزیشده تولید میکند. برخلاف تصور عمومی، هدف اصلی مدل هوش مصنوعی، شبیهسازی کامل هوش انسانی نیست، بلکه تمرکز آن بر انجام وظایف خاص به صورت خودکار و کارآمد است.
یکی از نمونههای اولیه و موفق مدل هوش مصنوعی را میتوان در برنامههای بازی شطرنج و منچ در دهه ۱۹۵۰ مشاهده کرد. این برنامهها به گونهای طراحی شده بودند که حرکات خود را بر اساس تصمیمات حریف انسانی تنظیم کنند، نه اینکه صرفاً از یک سری حرکات از پیش تعیینشده پیروی نمایند.
این قابلیت، نقطه عطفی در تاریخچه توسعه مدل هوش مصنوعی بود و نشان داد که چگونه این مدل میتواند در موقعیتهای پویا عمل کند. امروزه، مدل هوش مصنوعی در حوزههای متنوعی از جمله پزشکی (مطالعه بیشتر: تشخیص بیماری با هوش مصنوعی، نقش هوش مصنوعی در پزشکی و تشخیص سرطان)، حملونقل، آموزش و حتی هنر به کار گرفته میشود. اما آنچه این مدل را از دیگر فناوریها متمایز میکند، نوع الگوریتمها و دادههایی است که برای آموزش آن مورد استفاده قرار میگیرد.

انواع مدل هوش مصنوعی و کاربردهای آن
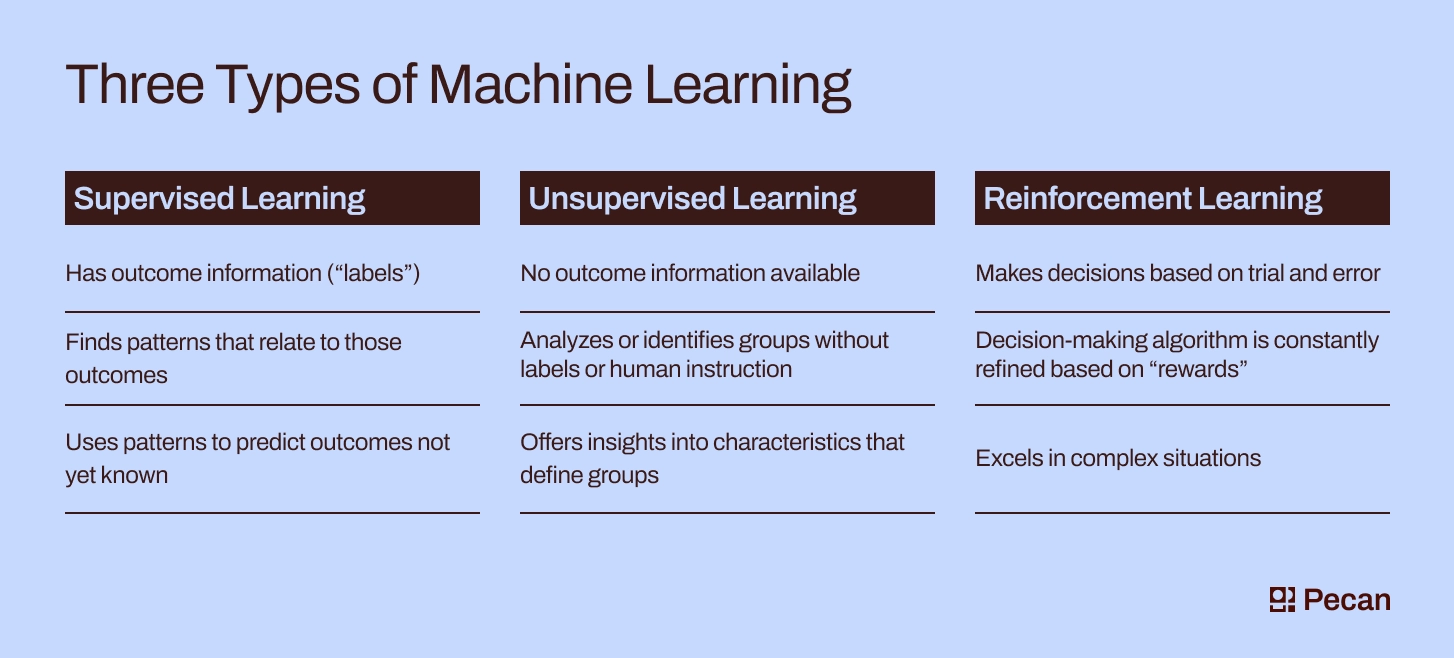
مدل هوش مصنوعی را میتوان بر اساس روشها و کاربردهایش به دستههای مختلفی تقسیم کرد. یکی از رایجترین دستهبندیها، تقسیمبندی بر اساس نوع یادگیری است که شامل یادگیری نظارتشده (Supervided Learning)، یادگیری بدون نظارت (Unsupervised Learning) و یادگیری تقویتی (Reinforcement Learning) میشود. هر یک از این روشها برای حل مسائل خاصی بهینهسازی شدهاند و انتخاب مدل هوش مصنوعی مناسب، بستگی به نوع دادهها و هدف نهایی دارد.
در یادگیری نظارتشده، مدل هوش مصنوعی با استفاده از دادههای برچسبدار (Labeled Data) آموزش داده میشود. به عنوان مثال، اگر بخواهیم یک مدل هوش مصنوعی برای تشخیص بیماریهای پوستی طراحی کنیم، باید مجموعهای از تصاویر پوست را به همراه برچسبهایی که نشاندهنده وضعیت سلامت یا بیماری هستند، به مدل ارائه دهیم. این مدل با تحلیل ویژگیهای موجود در تصاویر، یاد میگیرد که چگونه بین پوست سالم و بیمار تمایز قائل شود. این روش در حوزههایی مانند تشخیص پزشکی یا پیشبینی قیمتها بسیار پرکاربرد است.
در مقابل، یادگیری بدون نظارت به دادههای برچسبدار نیازی ندارد. در این روش، مدل هوش مصنوعی الگوهای پنهان در دادهها را شناسایی کرده و دادهها را به گروههایی تقسیم میکند. این روش در سیستمهای توصیهگر (Recommendation Systems) مانند آنچه در پلتفرمهای فروش آنلاین استفاده میشود، بسیار موثر است.
یادگیری تقویتی، رویکردی متفاوت است که در آن مدل هوش مصنوعی از طریق آزمون و خطا یاد میگیرد. در این روش، مدل با دریافت پاداش یا جریمه بر اساس تصمیمات خود، به تدریج عملکردش را بهبود میبخشد. این رویکرد در فناوریهایی مانند خودروهای خودران یا سیستمهای پیشنهاد محتوا در شبکههای اجتماعی بسیار موثر است.
یکی از پیشرفتهترین زیرشاخههای یادگیری بدون نظارت، یادگیری عمیق (Deep Learning) است که از شبکههای عصبی چندلایه برای شبیهسازی عملکرد مغز انسان استفاده میکند. مدل هوش مصنوعی مبتنی بر یادگیری عمیق، مانند مدلهای زبان بزرگ (LLM)، در کاربردهایی مانند تولید متن، ترجمه زبان و حتی خلق آثار هنری به کار گرفته میشود. این مدل به دلیل نیاز به منابع محاسباتی بالا، معمولاً در محیطهای ابری یا با استفاده از سختافزارهای پیشرفته اجرا میشود.
تفاوت مدلهای مولد و متمایزگر در هوش مصنوعی
یکی از روشهای کلیدی برای تمایز بین انواع مدل هوش مصنوعی، بررسی نحوه مدلسازی دادهها توسط آن است. بر این اساس، مدلها به دو دسته اصلی مولد (Generative) و متمایزگر (Discriminative) تقسیم میشوند. این تمایز، درک عمیقتری از عملکرد مدل هوش مصنوعی و کاربردهای آن ارائه میدهد.
مدل هوش مصنوعی مولد، دادهها را به گونهای مدلسازی میکند که بتواند نمونههای جدیدی از داده تولید نماید. این مدل معمولاً بر اساس یادگیری بدون نظارت عمل میکند و هدفش پیشبینی احتمال وقوع دادهها در یک فضای مشخص است. به عنوان مثال، یک مدل هوش مصنوعی مولد که برای تولید متن طراحی شده، میتواند با تحلیل متون موجود، جملاتی جدید و منطقی تولید کند. این قابلیت در ابزارهایی مانند چتباتها یا سیستمهای تکمیل خودکار متن بسیار پرکاربرد است.
در مقابل، مدل هوش مصنوعی متمایزگر بر تمایز بین دستههای مختلف دادهها تمرکز دارد. این مدل معمولاً از یادگیری نظارتشده استفاده میکند و هدفش پیشبینی احتمال تعلق یک داده به یک دسته خاص است. به عنوان مثال، یک مدل هوش مصنوعی متمایزگر در حوزه بینایی کامپیوتری میتواند یاد بگیرد که چگونه یک تصویر را با تمرکز بر ویژگیهای کلیدی که این دو را از هم متمایز میکند، به عنوان “پرنده” یا “هواپیما” طبقهبندی کند،
این مدل به دلیل نیاز به منابع محاسباتی کمتر نسبت به مدل مولد، در کاربردهایی مانند تحلیل احساسات یا تشخیص تقلب بسیار موثر است. جالب است بدانید که بسیاری از سیستمهای پیشرفته هوش مصنوعی از ترکیب این دو نوع مدل استفاده میکنند. به عنوان مثال، در شبکههای مولد تخاصمی (GAN)، یک مدل هوش مصنوعی مولد دادههای جدید تولید میکند و یک مدل متمایزگر تلاش میکند تشخیص دهد که آیا این دادهها واقعی هستند یا خیر.
مدل هوش مصنوعی بنیادی: آینده فناوری هوش مصنوعی
مدل هوش مصنوعی در حال تحول سریع است و یکی از مهمترین تحولات در این حوزه، ظهور مدل هوش مصنوعی بنیادی یا پایهای (Foundation Model) است. این مدل که بر روی مجموعه دادههای عظیم و بدون برچسب آموزش داده میشود، قابلیت انجام وظایف متنوعی را دارد و میتواند با تنظیم دقیق (Fine-Tuning) برای کاربردهای خاص بهینه شود. برخلاف مدلهای سنتی که برای یک وظیفه خاص طراحی و آموزش داده میشدند، مدل هوش مصنوعی بنیادی به عنوان یک زیرساخت عمومی عمل میکند که میتوان آن را برای طیف گستردهای از کاربردها مورد استفاده قرار داد. این رویکرد نه تنها زمان و هزینه توسعه را کاهش میدهد، بلکه امکان استفاده از یک مدل واحد برای چندین کاربرد را فراهم میکند.
به عنوان مثال، یک مدل هوش مصنوعی بنیادی که برای پردازش زبان طبیعی طراحی شده، میتواند با تنظیمات جزئی برای وظایفی مانند ترجمه زبان، تولید محتوا، پاسخ به سوالات تخصصی یا حتی تحلیل احساسات مورد استفاده قرار گیرد. این انعطافپذیری، مدل هوش مصنوعی بنیادی را به یکی از قدرتمندترین ابزارها در حوزه هوش مصنوعی تبدیل کرده است. مدلهای زبان بزرگ (LLM) مانند GPT-3 یا BERT نمونههای بارزی از مدل هوش مصنوعی بنیادی هستند که بر روی میلیاردها پارامتر آموزش دیدهاند و توانایی انجام وظایف متنوعی را دارند. این مدل با استفاده از تکنیکهای یادگیری عمیق و معماریهایی مانند ترنسفورمرها (Transformers) طراحی شده است که به آن امکان میدهد الگوهای پیچیدهای را در دادهها شناسایی کند.
یکی از مزایای کلیدی مدل هوش مصنوعی بنیادی، توانایی آن در یادگیری عمومی (General Learning) است. این مدل با آموزش بر روی دادههای متنوع و بدون برچسب، دانش گستردهای از جهان به دست میآورد که میتواند به عنوان پایهای برای یادگیری وظایف خاص استفاده شود. به عنوان مثال، یک مدل هوش مصنوعی بنیادی که بر روی متون اینترنتی آموزش دیده، میتواند اطلاعاتی در مورد فرهنگ، تاریخ، علم و حتی زبانهای مختلف داشته باشد، بدون اینکه به طور خاص برای این موضوعات آموزش دیده باشد. این قابلیت، مدل هوش مصنوعی بنیادی را به ابزاری ایدهآل برای توسعهدهندگان تبدیل کرده است که میخواهند با صرف کمترین منابع، سیستمهای هوش مصنوعی پیشرفتهای ایجاد کنند.
با این حال، توسعه و استفاده از مدل هوش مصنوعی بنیادی با چالشهایی نیز همراه است. یکی از بزرگترین چالشها، نیاز به دادههای آموزشی عظیم و قدرت محاسباتی بالا است. مدل پیشرفته مانند مدلهای زبان بزرگ، گاهی میلیاردها پارامتر دارد که آموزش آن نیازمند زیرساختهای محاسباتی پیشرفته و مصرف انرژی قابل توجه است. این موضوع نه تنها هزینهها را افزایش میدهد، بلکه نگرانیهایی در مورد تاثیرات زیستمحیطی نیز ایجاد میکند. به همین دلیل، پژوهشگران در حال بررسی روشهایی مانند تنظیم پارامترهای کارآمد (Efficient Fine-Tuning) یا استفاده از مدلهای فشردهتر هستند تا این مشکلات را کاهش دهند.
چالش دیگر، مسئله تعصب در دادههاست. از آنجا که مدل هوش مصنوعی بنیادی بر روی دادههای گسترده و بدون برچسب آموزش داده میشود، ممکن است تعصبات موجود در این دادهها را جذب کند و در نتیجه تصمیمات ناعادلانهای بگیرد. به عنوان مثال، یک مدل هوش مصنوعی بنیادی که بر روی متون اینترنتی آموزش دیده، ممکن است دیدگاههای خاصی را تقویت کند یا برخی گروهها را نادیده بگیرد. برای مقابله با این مشکل، روشهایی مانند استفاده از دادههای مصنوعی یا الگوریتمهای اصلاح تعصب در حال توسعه هستند. همچنین، شفافیت در مورد دادههای آموزشی و فرآیند توسعه مدل، یکی از موضوعات مهمی است که در آینده مدل هوش مصنوعی بنیادی باید به آن توجه بیشتری شود.
آینده مدل هوش مصنوعی بنیادی به سمت توسعه مدلهایی کارآمدتر، پایدارتر و عادلانهتر حرکت میکند. یکی از نوآوریهای اخیر در این حوزه، استفاده از تکنیکهای تنظیم سریع (Prompt Tuning) است که به جای تغییر کامل مدل، از نشانههای ورودی برای هدایت مدل به سمت وظایف خاص استفاده میکند. این روش نه تنها مصرف انرژی را کاهش میدهد، بلکه امکان استفاده از مدل هوش مصنوعی بنیادی در دستگاههای با منابع محدود را نیز فراهم میکند. علاوه بر این، انتظار میرود که مدل هوش مصنوعی بنیادی در آینده به سمت چندوظیفگی (Multitasking) و چندزبانگی (Multilingualism) بیشتری حرکت کند، به طوری که بتواند به طور همزمان چندین زبان و وظیفه را پشتیبانی کند.
در نهایت، آزمایش و ارزیابی مدل هوش مصنوعی بنیادی نیز یکی از جنبههای حیاتی در توسعه آن است. روشهایی مانند اعتبارسنجی متقابل (Cross-Validation) به توسعهدهندگان کمک میکند تا عملکرد مدل را به دقت ارزیابی کنند و از مشکلاتی مانند بیشبرازش (Overfitting) یا کمبرازش (Underfitting) جلوگیری کنند. انتخاب معیارهای مناسب برای ارزیابی، مانند دقت، دقت پیشبینی (Precision) یا یادآوری (Recall) نیز نقش مهمی در اطمینان از کیفیت مدل دارد. با توجه به این پیشرفتها و چالشها، مدل هوش مصنوعی بنیادی نه تنها در بهبود زندگی روزمره ما نقش دارد، بلکه در حل مسائل پیچیده جهانی، از تغییرات اقلیمی گرفته تا مراقبتهای بهداشتی، نیز تاثیرگذار خواهد بود.
منبع : IBM




