

هوش مصنوعی (AI) به یکی از مهمترین ابزارها در زندگی روزمره و صنایع مختلف تبدیل شده است. از دستیار هوش مصنوعی گرفته تا سیستمهای تولید محتوا، مدلهای زبانی بزرگ (Large Language Models) و ابزارهای تحلیل داده، هوش مصنوعی در حال تغییر شکل دادن به نحوه تعامل ما با دنیای دیجیتال است. اما با وجود تمامی دستاوردها و جهشهای چشمگیر، هوش مصنوعی همچنان با چالشها و کاستیهایی روبهروست که یکی از مهمترین آنها پدیدهای به نام “توهم هوش مصنوعی” یا AI Hallucination است.
اگرچه این اصطلاح ممکن است کمی عجیب یا حتی ترسناک به نظر برسد، اما درک آن برای استفاده مسئولانه و ایمن از هوش مصنوعی ضروری است. در این مطلب، بهطور جامع به بررسی مفهوم توهم هوش مصنوعی، دلایل وقوع آن، مثالهای واقعی، تأثیراتش و راهکارهای کاهش آن میپردازیم تا شما بهعنوان یک کاربر یا توسعهدهنده، بتوانید با آگاهی بیشتری از این فناوری استفاده کنید.
توهم هوش مصنوعی چیست؟
توهم هوش مصنوعی (AI Hallucination) به وضعیتی اشاره دارد که یک مدل هوش مصنوعی اطلاعاتی را تولید میکند که به ظاهر درست و منطقی به نظر میرسد، اما در واقع نادرست، ساختگی یا کاملاً بیمعنی است. به عبارت دیگر، هوش مصنوعی در این حالت دچار “توهم” میشود و اطلاعاتی را ارائه میدهد که هیچ پایه و اساسی در واقعیت ندارد. این مشکل بهویژه در مدلهای زبانی بزرگ که برای تولید متن، پاسخ به سؤالات یا حتی خلق محتوای خلاقانه طراحی شدهاند، شایع است. نکتهای که توهم هوش مصنوعی را خطرناک میکند، این است که خروجیهای آن اغلب بسیار متقاعدکننده هستند و کاربران ممکن است بهراحتی آنها را بهعنوان حقیقت بپذیرند.
برای درک بهتر این مفهوم، تصور کنید از یک مدل هوش مصنوعی درباره یک رویداد تاریخی سؤالی بپرسید. مدل ممکن است پاسخی ارائه دهد که پر از جزئیات به نظر میرسد، اما در واقع هیچکدام از این جزئیات واقعی نیستند و صرفاً توسط مدل “اختراع” شدهاند. این پدیده زمانی مشکلساز میشود که کاربران بدون بررسی صحت اطلاعات، به این پاسخها اعتماد کرده و از آنها در تصمیمگیریهای مهم استفاده کنند.

چرا توهم هوش مصنوعی رخ میدهد؟
برای درک دلایل وقوع توهم هوش مصنوعی، ابتدا باید به نحوه عملکرد مدلهای هوش مصنوعی، بهویژه مدلهای زبانی، نگاهی بیندازیم. این مدلها بر اساس دادههای عظیمی که در طول فرآیند آموزش به آنها داده میشود، کار میکنند. آنها الگوهای موجود در دادهها را شناسایی کرده و بر اساس این الگوها، پاسخهایی تولید میکنند. با این حال، این مدلها فهم واقعی از جهان ندارند؛ آنها صرفاً ماشینهای پیشبینی کنندهای هستند که در تلاشند تا محتملترین کلمات یا جملات را بر اساس دادههای آموزشی خود تولید کنند. اینجاست که مشکل توهم هوش مصنوعی ریشه میگیرد. در ادامه، به برخی از دلایل اصلی وقوع این پدیده میپردازیم.
یکی از دلایل اصلی توهم هوش مصنوعی، محدودیتها و نقصهای موجود در دادههای آموزشی است. اگر دادههایی که یک مدل با آنها آموزش دیده است، ناقص، نادرست یا دارای سوگیری باشند، مدل ممکن است خروجیهای نادرستی تولید کند. برای مثال، اگر یک مدل زبانی با مقالاتی آموزش دیده باشد که اطلاعات تاریخی غیردقیق دارند، ممکن است این اطلاعات نادرست را بهعنوان واقعیت ارائه دهد. علاوه بر این، مدلهای هوش مصنوعی گاهی اوقات برای پر کردن شکافهای اطلاعاتی خود، به “حدس زدن” روی میآورند. این حدسها ممکن است به نظر منطقی بیایند، اما در واقع هیچ پایه واقعی ندارند.
دلیل دیگر، طراحی خود مدلهاست. بسیاری از مدلهای زبانی به گونهای طراحی شدهاند که همیشه پاسخی ارائه دهند، حتی زمانی که اطلاعات کافی برای ارائه پاسخ دقیق ندارند. این ویژگی که گاهی بهعنوان “اعتماد بیش از حد” مدل شناخته میشود، میتواند منجر به تولید اطلاعات نادرست شود. در واقع، مدل به جای اینکه بگوید “نمیدانم” یا “اطلاعات کافی ندارم”، ترجیح میدهد پاسخی تولید کند که ممکن است کاملاً ساختگی باشد.
مثالهای واقعی از توهم هوش مصنوعی
برای اینکه درک بهتری از توهم هوش مصنوعی داشته باشیم، بیایید به چند مثال واقعی از این پدیده نگاه کنیم. این مثالها نشان میدهند که چگونه توهم هوش مصنوعی میتواند در موقعیتهای مختلف ظاهر شود و چه تأثیراتی به همراه داشته باشد.
فرض کنید از یک مدل زبانی میخواهید مقالهای درباره یک دانشمند خیالی به نام “دکتر آلفرد زیمرمن” بنویسد که در سال ۱۹۵۰ برنده جایزه نوبل فیزیک شده است. اگرچه این شخصیت کاملاً خیالی است، مدل ممکن است مقالهای بسیار مفصل و متقاعدکننده درباره زندگی او، دستاوردهایش و حتی نقلقولهایی از او تولید کند. این اطلاعات ممکن است به قدری واقعی به نظر برسند که یک کاربر عادی بدون بررسی بیشتر، آنها را باور کند. این مثال نشان میدهد که چگونه توهم هوش مصنوعی میتواند اطلاعات کاملاً جعلی را به شکلی بسیار معتبر ارائه دهد.

مثال دیگر میتواند در حوزه پزشکی باشد، جایی که اعتماد به خروجیهای نادرست هوش مصنوعی میتواند عواقب جدی به همراه داشته باشد. فرض کنید یک پزشک از یک مدل هوش مصنوعی برای تشخیص بیماری یک بیمار استفاده میکند. اگر مدل، اطلاعاتی نادرست درباره علائم یا درمان یک بیماری ارائه دهد، ممکن است پزشک تصمیمات نادرستی بگیرد که سلامت بیمار را به خطر بیندازد. این مثال اهمیت درک و مدیریت توهم هوش مصنوعی را در حوزههای حساس مانند پزشکی نشان میدهد.
تأثیرات توهم هوش مصنوعی
توهم هوش مصنوعی میتواند تأثیرات گستردهای در حوزههای مختلف داشته باشد، از زندگی روزمره گرفته تا صنایع حرفهای و حتی مسائل اخلاقی و اجتماعی. یکی از مهمترین تأثیرات این پدیده، کاهش اعتماد کاربران به فناوری هوش مصنوعی است. اگر کاربران بهطور مداوم با اطلاعات نادرست مواجه شوند، ممکن است اعتماد خود را به این ابزارها از دست بدهند و از استفاده از آنها خودداری کنند. این مسئله بهویژه در حوزههایی مانند آموزش، رسانه و تحقیقات علمی میتواند مشکلساز باشد.
در حوزه رسانه و تولید محتوا، توهم هوش مصنوعی میتواند به انتشار اخبار جعلی و اطلاعات نادرست منجر شود. تصور کنید از یک مدل هوش مصنوعی برای نوشتن مقاله خبری استفاده شود و اطلاعاتی درباره یک رویداد سیاسی یا اجتماعی تولید کند که کاملاً نادرست است. انتشار چنین مقالاتی میتواند تأثیرات منفی گستردهای بر افکار عمومی و حتی سیاستگذاریها داشته باشد.
علاوه بر موارد گفته شده، در حوزههای حرفهای مانند حقوق و مهندسی نیز توهم هوش مصنوعی میتواند عواقب جدی به همراه داشته باشد. برای مثال، اگر یک مدل هوش مصنوعی در یک پرونده حقوقی اطلاعاتی نادرست درباره قوانین یا شواهد ارائه دهد، ممکن است منجر به تصمیمگیریهای ناعادلانه شود. به همین دلیل، استفاده مسئولانه از هوش مصنوعی و آگاهی از محدودیتهای آن در این حوزهها از اهمیت ویژهای برخوردار است.
نرخ توهم هوش مصنوعی
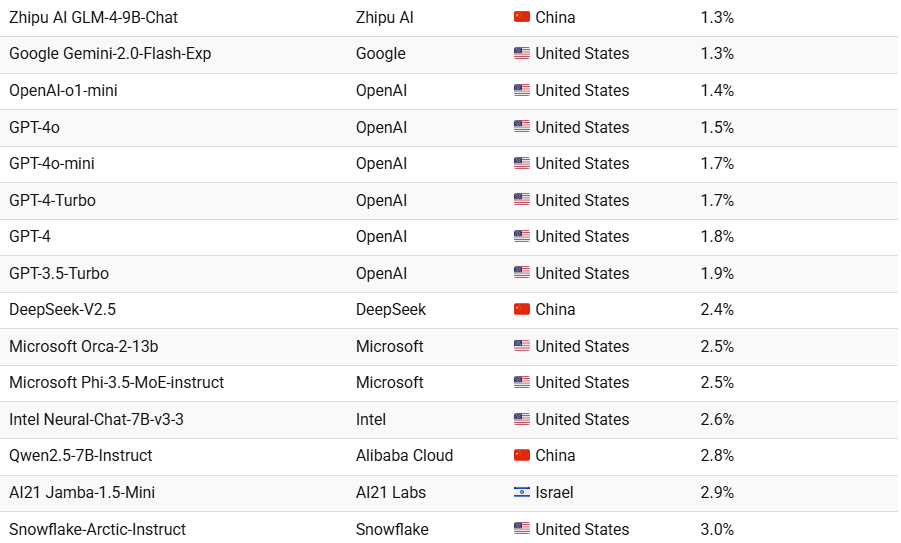
یکی از معیارهای مهم در ارزیابی عملکرد مدلهای زبانی، نرخ توهم آنهاست. نرخ توهم نشاندهنده میزان اطلاعاتی است که یک مدل بهصورت نادرست یا بدون پشتوانه واقعی تولید میکند. در ادامه، فهرستی از ۱۵ مدل زبانی برتر با پایینترین نرخ توهم، همراه با شرکت سازنده و کشور مبدأ آنها ارائه شده است. مدلهایی مانند Zhipu AI GLM-4-9B-Chat ،OpenAI-o1-mini و OpenAI-4o-mini که جزء مدلهای کوچکتر یا تخصصیتر هستند، برخی از پایینترین نرخهای توهم را در میان تمامی مدلها دارند.
بر اساس گزارش Vectara، مدلهای کوچکتر میتوانند نرخهای توهمی مشابه یا حتی بهتر (پایینتر) از مدلهای زبانی بزرگتر داشته باشند. اندازهگیری نرخ توهم بهویژه در کاربردهای حساس مانند پزشکی، حقوق و امور مالی از اهمیت فزایندهای برخوردار است. اگرچه مدلهای بزرگتر بهطور کلی عملکرد بهتری نسبت به مدلهای کوچکتر دارند و بهطور مداوم برای دستیابی به نتایج بهتر گسترش مییابند، اما معایبی مانند هزینههای بالا، سرعت پایین در استنتاج و پیچیدگی نیز دارند.
با این حال، مدلهای کوچکتر در حال کم کردن این فاصله هستند و بسیاری از آنها در وظایف خاص عملکرد خوبی از خود نشان میدهند. برای مثال، مطالعهای نشان داد که مدل کوچکتر Mistral 8x7B توانسته است توهمات را در متون تولیدشده توسط هوش مصنوعی کاهش دهد. در میان مدلهای پایه، مدل Google Gemini 2.0 با اختلاف ناچیز ۰.۲ درصد در نرخ توهم نسبت به OpenAI GPT-4O، عملکرد بهتری دارد. با این حال، بهطور کلی، نسخههای مختلف GPT-4 (مانند Turbo، Mini و استاندارد) در محدوده نرخ توهم ۱.۵ تا ۱.۸ درصد قرار دارند که نشاندهنده تمرکز قوی بر دقت در معماریهای مختلف این مدل است.
چگونه میتوان توهم هوش مصنوعی را کاهش داد؟
اگرچه توهم هوش مصنوعی یک مشکل جدی است، اما راهکارهایی برای کاهش آن وجود دارد. این راهکارها نیازمند همکاری بین توسعهدهندگان مدلهای هوش مصنوعی، کاربران و سیاستگذاران است. در ادامه، به برخی از مهمترین روشهای کاهش توهم هوش مصنوعی میپردازیم.
یکی از مهمترین راهکارها، بهبود کیفیت دادههای آموزشی است. توسعهدهندگان مدلهای هوش مصنوعی باید تلاش کنند تا دادههایی که برای آموزش مدلها استفاده میکنند، دقیق، بهروز و عاری از سوگیری باشند. این کار میتواند به کاهش احتمال تولید اطلاعات نادرست توسط مدلها کمک کند. علاوه بر این، استفاده از تکنیکهای اعتبارسنجی دادهها و بررسی منابع اطلاعاتی میتواند دقت مدلها را ارتقا دهد.
راهکار دیگر، طراحی مدلهایی است که محدودیتهای خود را بهخوبی نشان دهند. به جای اینکه مدلها همیشه پاسخی ارائه دهند، میتوان آنها را طوری طراحی کرد که در صورت عدم اطمینان، به کاربر اطلاع دهند که اطلاعات کافی ندارند یا پاسخ ممکن است نادرست باشد. این ویژگی میتواند به کاربران کمک کند تا با احتیاط بیشتری از خروجیهای مدل استفاده کنند.
آموزش کاربران نیز نقش مهمی در کاهش تأثیرات منفی توهم هوش مصنوعی دارد. کاربران باید آگاه باشند که خروجیهای مدلهای هوش مصنوعی همیشه قابل اعتماد نیستند و باید اطلاعات ارائهشده را از منابع معتبر بررسی کنند. این موضوع بهویژه در حوزههایی مانند آموزش و رسانه اهمیت دارد، جایی که اطلاعات نادرست میتواند تأثیرات قابل توجهی داشته باشد.
سیاستگذاری و تنظیم مقررات نیز میتواند به کاهش توهم هوش مصنوعی کمک کند. دولتها و سازمانهای بینالمللی میتوانند استانداردهایی برای توسعه و استفاده از مدلهای هوش مصنوعی تعیین کنند تا از سوءاستفاده یا انتشار اطلاعات نادرست جلوگیری شود. این استانداردها میتوانند شامل الزاماتی برای شفافیت در عملکرد مدلها و مسئولیتپذیری توسعهدهندگان باشند.
با توجه به سرعت پیشرفت فناوری هوش مصنوعی، انتظار میرود که در آینده، تلاشهای بیشتری برای کاهش توهم هوش مصنوعی انجام شود. توسعه مدلهایی با دقت بالاتر، استفاده از تکنیکهای پیشرفتهتر در یادگیری ماشین و افزایش آگاهی عمومی درباره محدودیتهای این فناوری، همگی میتوانند به کاهش این مشکل کمک کنند. با این حال، باید به خاطر داشته باشیم که هوش مصنوعی، مانند هر فناوری دیگری، ابزاری است که باید با دقت و مسئولیت استفاده شود. درک توهم هوش مصنوعی و آگاهی از محدودیتهای آن، کلید استفاده ایمن و مؤثر از این فناوری است.
منبع: IBM ،Visualcapitalist




