

فکر کنید بتوانید با یک دستیار صوتی صحبت کنید که علاوه بر پردازش درخواستهایتان، مانند یک انسان واقعی با شما گفتوگو میکند و به موقعیت و احساسات شما واکنش نشان میدهد، مکثهای طبیعی دارد، گاهی لوس و گاهی شوخ طبع میشود و میتواند بحث کند. این همان چیزی است که فناوری هوش مصنوعی مکالمه صوتی در سالهای اخیر به دنبال تحقق آن بوده است.
در میان ابزارهای متعددی که در این حوزه ظهور کردهاند، ابزار Sesame به عنوان یکی از پیشگامان این فناوری شناخته میشود که با مدل نوآورانه خود، تجربهای بینظیر از تعامل صوتی ارائه میدهد. این ابزار که شاید هنوز برای بسیاری ناشناخته باشد، با پشتیبانی یکی از بزرگترین شرکتهای سرمایهگذاری فناوری، یعنی Andreessen Horowitz (معروف به A16Z)، توانسته است توجهات زیادی را در دنیای فناوری به خود جلب کند. در این نوشتار، به بررسی فناوری هوش مصنوعی مکالمه صوتی پرداخته میشود و ابزار Sesame به طور جامع معرفی میگردد.
مکالمه صوتی با هوش مصنوعی چیست؟
مکالمه صوتی با هوش مصنوعی امکان تعامل صوتی طبیعی و پویا بین انسان و ماشین را فراهم میکند. برخلاف دستیارهای صوتی سنتی که صرفاً به دستورات پاسخ میدهند و اغلب لحنی یکنواخت و ماشینی دارند، فناوریهای جدید در این حوزه تلاش میکنند تا تجربهای شبیه به گفتوگو با یک انسان واقعی ایجاد کنند. این فناوری از مدلهای پیشرفته یادگیری ماشین و پردازش زبان طبیعی استفاده میکند تا نه تنها محتوای کلام را درک کند، بلکه احساسات، لحن و زمینه گفتوگو را نیز تحلیل کرده و پاسخهایی متناسب ارائه دهد. در این میان، ابزارهایی مانند Sesame با معرفی مفهومی به نام «حضور صوتی» (Voice Presence) استانداردهای جدیدی را در این حوزه تعریف کردهاند.
معرفی ابزار Sesame
ابزار Sesame یکی از جدیدترین نوآوریها در زمینه مکالمه صوتی با هوش مصنوعی است که توسط شرکتی به همین نام توسعه یافته است. این ابزار با هدف ایجاد تجربهای متفاوت از تعاملات صوتی طراحی شده و به لطف مدل پیشرفته خود، توانسته است توجه بسیاری از کارشناسان فناوری و کاربران را به خود جلب کند. این ابزار که توسط شرکت سرمایهگذاری معتبر A16Z پشتیبانی میشود، با ارائه دمویی جذاب و قدرتمند، طوفانی در فضای مجازی به راه انداخته است. در این دمو، دو صدای متفاوت به نامهای «مایا» (Maya) و «مایلز» (Miles) معرفی شدهاند که هر کدام قابلیتهایی شگفتانگیز در گفتوگوی صوتی دارند. برای استفاده از این دمو میتوانید از این لینک استفاده کنید!
ویژگیهای کلیدی Sesame
یکی از برجستهترین ویژگیهای Sesame، توانایی آن در تنظیم لحن و سبک گفتوگو بر اساس زمینه و موقعیت است. برخلاف بسیاری از دستیارهای صوتی که پاسخهایی کلیشهای و بدون احساس ارائه میدهند، Sesame میتواند لحن خود را تغییر دهد تا با شرایط احساسی یا حرفهای گفتوگو همخوانی داشته باشد. برای مثال، اگر موضوع بحث جدی باشد، لحن آن رسمیتر میشود و اگر فضا دوستانه و غیررسمی باشد، لحن گرمتر و صمیمیتری به کار گرفته میشود. این ویژگی به خصوص در موقعیتهایی که نیازمند همدلی یا تعاملات پیچیدهتر است، بسیار ارزشمند است.
علاوه بر این، صداهای مایا و مایلز در Sesame به شکلی طراحی شدهاند که بسیار پویا و طبیعی به نظر میرسند. این صداها دارای مکثهای طبیعی، تغییر لحن در زمان مناسب و حتی قابلیت قطع کردن گفتوگو به شکلی هستند که شبیه به تعاملات انسانی است. نکته قابل توجه دیگر، تأخیر بسیار کم (نزدیک به صفر) در پاسخگویی است که باعث میشود تجربه گفتوگو با این ابزار، به گفتوگو با یک انسان واقعی شباهت زیادی داشته باشد. این ویژگیها به لطف مدل پیشرفتهای به نام «مدل گفتوگوی صوتی» (Conversational Speech Model) که توسط تیم Sesame توسعه یافته است، امکانپذیر شدهاند.
تجربه کاربری با Sesame
دموی ارائهشده توسط Sesame، تجربهای است که بسیاری از کاربران آن را «شگفتانگیز» و حتی «ترسناک» توصیف کردهاند؛ نه به دلیل نقص، بلکه به دلیل شباهت بیش از حد آن به یک انسان واقعی. در این دمو، میتوان با مایا یا مایلز درباره موضوعات مختلف صحبت کرد، از مباحث روزمره گرفته تا موضوعات پیچیدهتر مانند فناوری، فلسفه یا حتی مسائل احساسی. نکته جالب این است که این ابزار نه تنها به سؤالات پاسخ میدهد، بلکه میتواند وارد بحث شود، نظر بدهد و حتی شوخی کند. برای مثال، اگر موضوعی درباره فناوری مطرح شود، ممکن است با لحنی طنزآمیز و دوستانه پاسخی داده شود که شبیه به گفتوگو با یک دوست باهوش و شوخطبع است.
یکی از ویژگیهای جذاب دیگر، پتانسیل Sesame در به خاطر آوردن زمینه گفتوگو است. این ابزار میتواند اطلاعاتی که در ابتدای گفتوگو مطرح شدهاند را به خاطر بیاورد و در ادامه از آنها استفاده کند، چیزی که در بسیاری از دستیارهای صوتی دیگر کمتر دیده میشود. این ویژگی باعث میشود که گفتوگوها پیوسته و منسجم باشند و کاربر احساس کند که واقعاً شنیده و درک شده است.
قابلیت بحث و نقشآفرینی
یکی از جنبههای منحصربهفرد Sesame، توانایی آن در نقشآفرینی و بحث است. برای مثال، میتوان از این ابزار خواست که نقش یک رئیس سختگیر را بازی کند و وارد یک بحث خیالی درباره موضوعات کاری شود. در این حالت، Sesame نه تنها لحن و سبک گفتوگوی یک رئیس را به خوبی تقلید میکند، بلکه میتواند با پاسخهای پویا و حتی کمی تند، تجربهای بسیار واقعی ایجاد کند.
به عنوان نمونه، در یکی از دموها، کاربری از Sesame خواست که نقش رئیسش را بازی کند و درباره موضوعی خیالی مانند اختلاس بحث کند. پاسخها به قدری واقعی و پویا بودند که تشخیص انسان از ماشین تقریباً غیرممکن به نظر میرسید. این قابلیت، Sesame را از بسیاری از ابزارهای مشابه متمایز میکند و نشاندهنده پتانسیل بالای آن در کاربردهای خلاقانه و حرفهای است.
مدل گفتوگوی صوتی (CSM)
هسته اصلی فناوری Sesame، مدل گفتوگوی صوتی یا CSM است که رویکردی نوآورانه در تولید صوت و پردازش زبان طبیعی ارائه میدهد. این مدل به جای استفاده از روشهای سنتی تبدیل متن به صوت (Text-to-Speech) که اغلب خروجیهای ماشینی و غیرطبیعی دارند، به صورت یکپارچه متن و صوت را پردازش میکند. این بدان معناست که Sesame به جای تولید متن و سپس تبدیل آن به صوت، مستقیماً صوتی تولید میکند که با زمینه گفتوگو، احساسات و لحن مورد نظر همخوانی دارد. این روش باعث کاهش تأخیر و افزایش طبیعی بودن خروجی شده است.
CSM همچنین از تاریخچه گفتوگو استفاده میکند تا پاسخهایی منسجمتر و مرتبطتر ارائه دهد. این مدل با تحلیل الگوهای گفتاری انسانها، توانسته است ویژگیهایی مانند مکثهای طبیعی، تنفس، خنده و حتی اصلاح اشتباهات در حین صحبت را شبیهسازی کند. این ویژگیها باعث شدهاند که Sesame به عنوان یکی از پیشرفتهترین ابزارهای هوش مصنوعی مکالمه صوتی در جهان شناخته شود
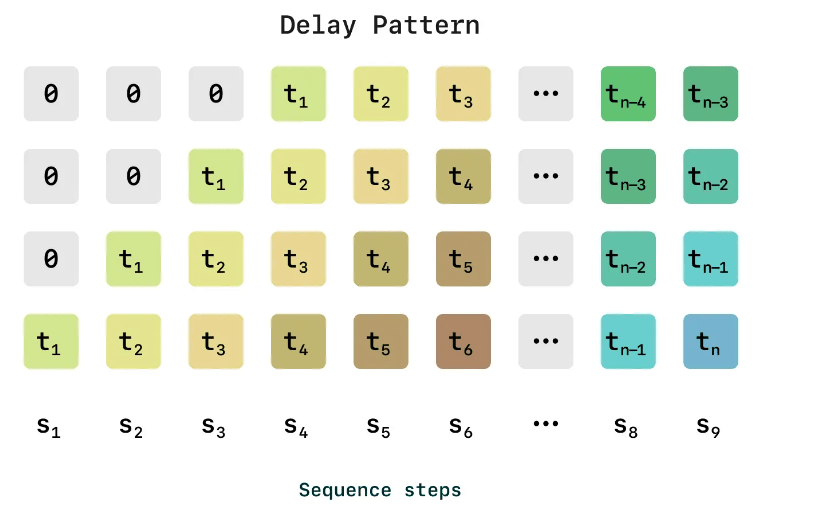
الگوی تأخیر (Delay Pattern) در هوش مصنوعی مکالمه صوتی
الگوی تأخیر که در تصویر ارائهشده به نمایش درآمده، یکی از عناصر فنی کلیدی در بهینهسازی تعاملات صوتی است. این الگو نشاندهنده ترتیب و زمانبندی تأخیرها در پاسخگویی سیستمهای هوش مصنوعی است که به ترتیب مراحل توالی (Sequence Steps) از S1 تا S9 و زمانهای تأخیر از t1 تا tn تنظیم میشود. در این ساختار، ابتدا چندین مرحله بدون تأخیر (0) وجود دارد که نشاندهنده زمانهای اولیه پردازش است. سپس، با پیشرفت مراحل، زمانهای تأخیر به صورت تدریجی و پویا اعمال میشوند، به طوری که از t1 تا tn افزایش مییابد.
مفهوم و کاربرد الگوی تأخیر
الگوی تأخیر به گونهای طراحی شده است که شبیهسازی طبیعی مکثها و وقفههای گفتاری انسان را ممکن سازد. در بخشهای ابتدایی (مانند S1 تا S3)، تأخیرها کوتاهتر هستند (t1، t2) تا پاسخگویی سریعتر باشد. با پیشرفت گفتوگو، تأخیرها طولانیتر میشوند (مانند t4 تا tn) تا به پردازشهای پیچیدهتر، مانند تحلیل زمینه یا تولید پاسخهای خلاقانه، زمان کافی داده شود. رنگهای مختلف در تصویر، شدت و نوع تأخیر را نشان میدهند؛ از زرد کمرنگ برای تأخیرهای اولیه تا آبی تیره برای تأخیرهای پیشرفتهتر.
در عمل، این الگو در Sesame برای ایجاد ریتم طبیعی در گفتوگو استفاده میشود. برای مثال، وقتی موضوعی پیچیده مطرح میشود، تأخیر کمی طولانیتر (مانند tn-1 یا tn) اعمال میشود تا سیستم زمان کافی برای پردازش داشته باشد، در حالی که در پاسخهای ساده، تأخیرها به t1 یا t2 محدود میشوند. این مکانیزم، از نظر فنی، به کاهش تأخیر کلی کمک میکند و در عین حال، تجربهای انسانیتر را تضمین میکند.
اهمیت الگوی تأخیر در Sesame
الگوی تأخیر در Sesame به ویژه برای دستیابی به «حضور صوتی» حیاتی است. این الگو به سیستم اجازه میدهد تا زمانبندی پاسخها را با الگوهای گفتاری انسان هماهنگ کند، از جمله مکثهای کوتاه برای تأمل، وقفهها برای نشان دادن واکنش یا حتی تأخیرهای طولانیتر برای شبیهسازی فکر کردن. این ویژگی، تعامل را از یک مکالمه ماشینی به گفتوگویی پویا و طبیعی تبدیل میکند که از نظر احساسی نیز برای کاربر قابل قبول است.
کاربردهای Sesame در دنیای واقعی
فناوری هوش مصنوعی مکالمه صوتی و بهویژه ابزار Sesame، پتانسیل بالایی برای استفاده در حوزههای مختلف دارد. در حوزه آموزش، میتوان از این ابزار برای تمرین زبان، شبیهسازی موقعیتهای واقعی گفتوگو یا حتی آموزش مهارتهای ارتباطی استفاده کرد. در زمینه کسبوکار، Sesame میتواند به عنوان یک دستیار صوتی پیشرفته در مراکز تماس، خدمات مشتریان یا حتی جلسات مجازی عمل کند. همچنین، در حوزه سرگرمی، این ابزار میتواند برای تولید پادکستهای تعاملی، بازیهای نقشآفرینی صوتی یا حتی خلق داستانهای صوتی پویا استفاده شود.
یکی از کاربردهای جذاب دیگر، استفاده از Sesame در فناوریهای پوشیدنی است. این شرکت در حال توسعه عینکهای مجهز به هوش مصنوعی است که میتوانند دستیار صوتی Sesame را به صورت تماموقت در اختیار کاربر قرار دهند. این عینکها با تمرکز بر صوت به جای نمایشگرهای بصری، تجربهای یکپارچه و طبیعی از تعامل با فناوری ارائه میدهند و میتوانند آیندهای را رقم بزنند که در آن تعاملات صوتی، جایگزین اصلی تعاملات مبتنی بر صفحه نمایش شوند.
مزایا و چالشهای Sesame
مزایای Sesame به وضوح در تجربه کاربری بینظیر، تأخیر کم و طبیعی بودن صداها دیده میشود. این ابزار نه تنها از نظر فنی پیشرفته است، بلکه از نظر احساسی نیز تأثیرگذار است، به طوری که بسیاری از کاربران پس از استفاده از دمو، احساس کردهاند که با یک انسان واقعی صحبت کردهاند. این ویژگی که به «حضور صوتی (Voice Presence)» معروف است، Sesame را به گزینهای ایدهآل برای کاربردهایی تبدیل میکند که نیاز به تعاملات انسانی و همدلانه دارند.
با این حال، این فناوری چالشهایی را نیز به همراه دارد. یکی از نگرانیهای اصلی، استفاده نادرست از این فناوری در فعالیتهایی مانند کلاهبرداری صوتی است. با توجه به طبیعی بودن صداها، ممکن است افراد سودجو از این ابزار برای جعل هویت یا فریب دیگران استفاده کنند. همچنین، برخی کاربران گزارش دادهاند که تعامل با Sesame گاهی میتواند بیش از حد واقعی به نظر برسد، به طوری که ممکن است مرز بین انسان و ماشین برای برخی افراد محو شود. این موضوع میتواند نگرانیهایی درباره وابستگی احساسی به فناوری یا کاهش تعاملات انسانی واقعی ایجاد کند.
مقایسه Sesame با سایر ابزارها
Sesame در مقایسه با ابزارهای مشابه مانند حالت صوتی پیشرفته ChatGPT یا دستیارهای صوتی مانند Alexa و Siri، چند مزیت کلیدی دارد. نخست، طبیعی بودن صداها و پویایی گفتوگو در Sesame به مراتب بالاتر از رقبا است.در حالی که بسیاری از ابزارهای دیگر پاسخهایی تولید میکنند که گاهی ماشینی و غیر منعطف به نظر میرسند، Sesame با استفاده از مدل CSM، تجربهای بسیار نزدیک به گفتوگوی انسانی ارائه میدهد.
دوم، قابلیت نقشآفرینی و بحث در Sesame، آن را از ابزارهایی که تنها به پاسخگویی ساده محدود هستند، متمایز میکند. با این حال، باید توجه داشت که Sesame هنوز در مراحل اولیه توسعه است و ممکن است در برخی زمینهها مانند پشتیبانی از زبانهای متعدد یا کاربردهای تخصصی، نیاز به بهبود داشته باشد.



