

یادگیری تقویتی (Reinforcement Learning) یکی از شاخههای پیشرفته یادگیری ماشین (Machine Learning) است که به ماشینها امکان میدهد از طریق تعامل با محیطهای پویا، رفتارهای پیچیدهای را بدون نیاز به برنامهنویسی صریح یا نظارت مستقیم انسانی یاد بگیرند. این روش، که از رفتارشناسی حیوانات الهام گرفته شده، در سالهای اخیر با پیشرفت در یادگیری عمیق و افزایش قدرت محاسباتی، به دستاوردهای چشمگیری در حوزه هوش مصنوعی دست یافته است.
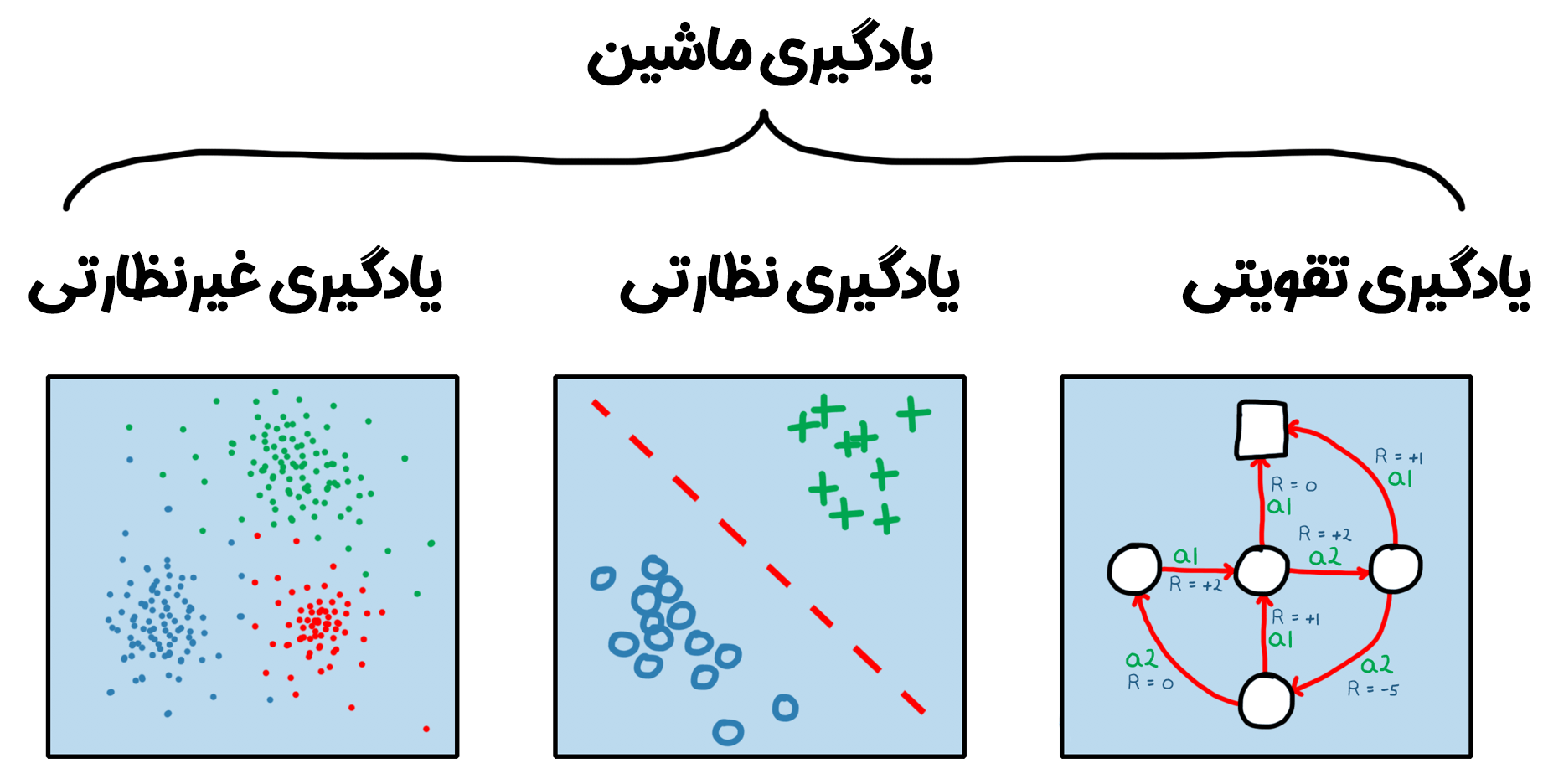
یادگیری تقویتی چیست؟
یادگیری تقویتی رویکردی در یادگیری ماشین است که در آن یک عامل نرمافزاری (Agent) از طریق آزمون و خطا در یک محیط پویا یاد میگیرد تا تصمیمهایی بگیرد که پاداش (Reward) را به حداکثر برساند. برخلاف روشهای یادگیری نظارتشده یا نظارتی، که به دادههای برچسبگذاریشده وابسته هستند، یا یادگیری غیرنظارتی، که الگوهای پنهان را در دادهها کشف میکند، یادگیری تقویتی نیازی به دادههای اولیه ندارد. در عوض، عامل از تعاملات خود با محیط داده تولید کرده و از آنها برای بهبود تصمیمگیریهایش استفاده میکند.
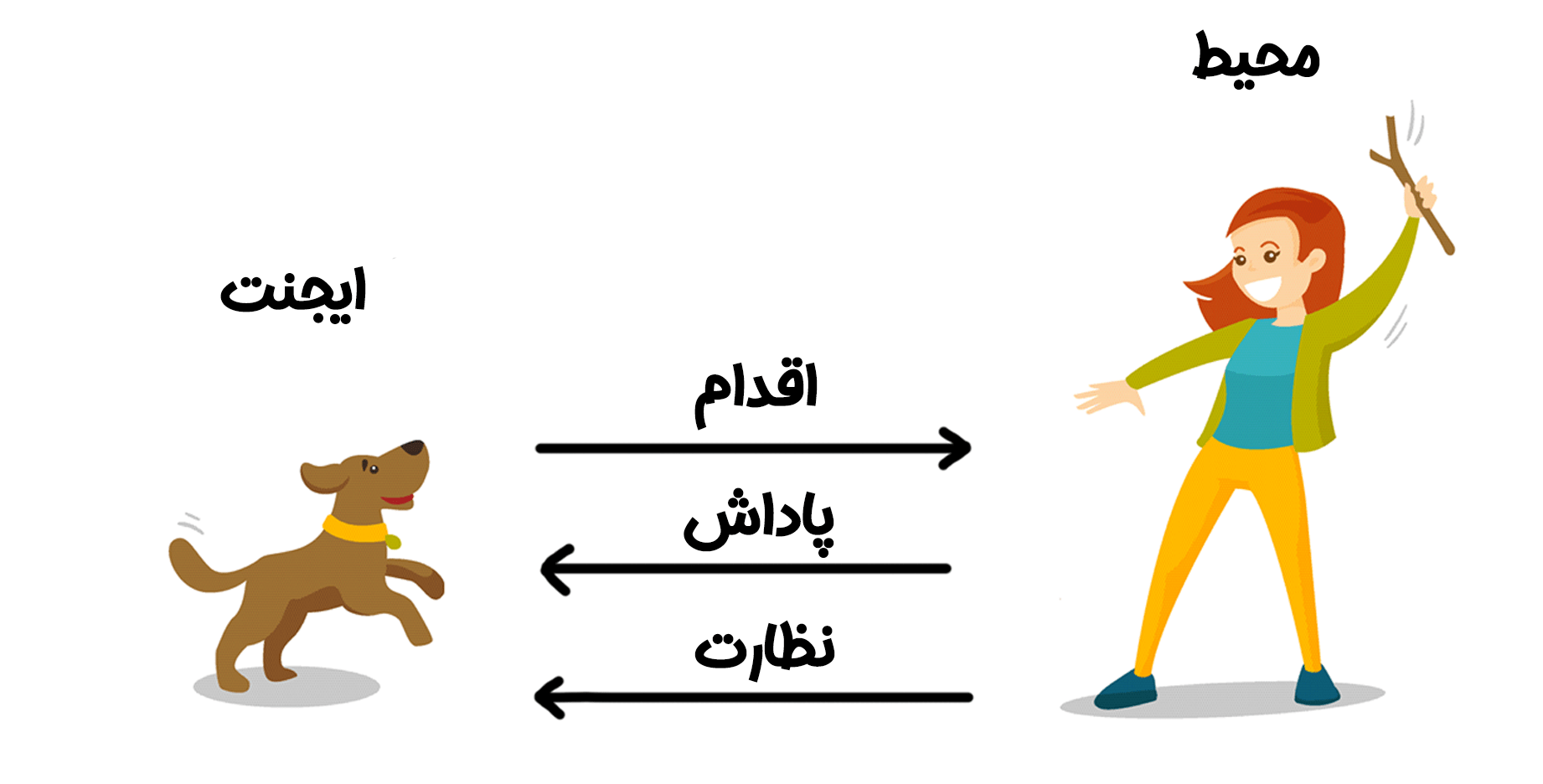
برای درک بهتر، فرض کنید یک سگ را آموزش میدهید تا با شنیدن دستور “بنشین” بنشیند. سگ (عامل) در محیطی شامل شما و فضای اطرافش عمل میکند. وقتی دستور “بنشین” را میدهید، سگ یک اقدام انجام میدهد، مثلاً مینشیند یا میچرخد. اگر اقدامش درست باشد، پاداشی مانند یک خوراکی دریافت میکند. در غیر این صورت، پاداشی نمیگیرد. با تکرار این فرآیند، سگ یاد میگیرد که کدام اقدامها به پاداش منجر میشوند. یادگیری تقویتی در هوش مصنوعی نیز به همین شکل عمل میکند، اما به جای سگ، یک الگوریتم کامپیوتری نقش عامل را ایفا میکند.
این روش در حوزههایی مانند بازیهای تختهای (مثل شطرنج و گو)، رباتیک و رانندگی خودکار موفقیتهای چشمگیری داشته است. به عنوان مثال، برنامه AlphaGo از شرکت DeepMind با استفاده از یادگیری تقویتی توانست قهرمان جهانی بازی گو را شکست دهد، موفقیتی که تا پیش از آن غیرممکن به نظر میرسید.
یادگیری تقویتی چگونه کار میکند؟
یادگیری تقویتی بر اساس تعامل سه جزء اصلی عمل میکند: عامل، محیط و پاداش. عامل تصمیمگیرندهای است که در محیطی مشخص عمل میکند. محیط شامل تمام عناصر خارجی است که عامل با آنها تعامل دارد، مانند قوانین یک بازی یا دینامیکهای یک خودرو. پاداش سیگنالی است که عملکرد عامل را ارزیابی میکند و هدف عامل، حداکثر کردن مجموع پاداشهای بلندمدت است.
فرآیند یادگیری تقویتی به این صورت است: عامل در هر مرحله یک مشاهده (Observation) از محیط دریافت میکند، مانند دادههای حسگرها در یک خودرو یا وضعیت مهرهها در یک بازی. سپس، بر اساس یک سیاست (Policy)، که نگاشتی از مشاهدات به اقدامات است، یک اقدام (Action) انجام میدهد. محیط به این اقدام واکنش نشان میدهد و یک پاداش (مثبت یا منفی) و یک مشاهده جدید به عامل ارائه میدهد. این چرخه بارها تکرار میشود تا عامل سیاست خود را بهبود دهد و بهترین اقدامات را برای دستیابی به پاداش بهینه انتخاب کند.
برای مثال، در یک سیستم رانندگی خودکار، کامپیوتر خودرو (عامل) از حسگرهایی مانند دوربین و لیدار دادههایی دریافت میکند. این دادهها مشاهدات هستند. کامپیوتر بر اساس این مشاهدات تصمیم میگیرد که فرمان را بچرخاند، ترمز کند یا شتاب دهد (اقدامات). اگر خودرو به درستی در یک پارکینگ قرار گیرد، پاداش مثبتی دریافت میکند. در غیر این صورت، مثلاً اگر به مانعی برخورد کند، پاداش منفی میگیرد. با تکرار این فرآیند، کامپیوتر یاد میگیرد که چگونه به طور ایمن پارک کند.
تفاوت یادگیری تقویتی با سایر روشهای یادگیری ماشین
یادگیری تقویتی در مقایسه با سایر روشهای یادگیری ماشین ویژگیهای متمایزی دارد. یادگیری نظارتشده برای پیشبینی یا طبقهبندی به دادههای برچسبگذاریشده نیاز دارد، مانند تشخیص تصاویر گربهها با استفاده از مجموعهای از تصاویر برچسبدار. یادگیری بدون نظارت الگوهای پنهان را در دادههای بدون برچسب کشف میکند، مانند خوشهبندی مشتریان بر اساس رفتار خرید. اما همانطور که پیشتر نیز به آن اشاره شد، یادگیری تقویتی نیازی به دادههای اولیه ندارد و از تعاملات پویا با محیط برای یادگیری استفاده میکند.
یادگیری تقویتی اغلب با یادگیری عمیق ترکیب میشود، که به آن یادگیری تقویتی عمیق (Deep Reinforcement Learning) میگویند. در این حالت، شبکههای عصبی عمیق برای مدلسازی سیاستها در مسائل پیچیده با فضاهای حالت و اقدام بزرگ استفاده میشوند. این ترکیب امکان حل مسائلی را فراهم کرده که با روشهای سنتی غیرممکن بودند، مانند تصمیمگیری در محیطهای پیچیده با دادههای چندبعدی.
کاربردهای یادگیری تقویتی
یادگیری تقویتی در حوزههای متنوعی کاربرد دارد. در ادامه، به برخی از مهمترین کاربردهای آن اشاره میکنیم:
رانندگی خودکار
یادگیری تقویتی در سیستمهای رانندگی خودکار برای تصمیمگیری در شرایط پیچیده استفاده میشود. برای مثال، یک خودرو میتواند با استفاده از دادههای حسگرهای دوربین و لیدار یاد بگیرد که چگونه در یک پارکینگ شلوغ پارک کند یا به موانع واکنش نشان دهد. این روش به خودرو امکان میدهد تا بدون نیاز به برنامهنویسی دستی برای هر سناریو، رفتارهای بهینه را یاد بگیرد.
رباتیک
در رباتیک، یادگیری تقویتی برای آموزش رباتها در انجام وظایف پیچیده مانند گرفتن اشیا، راه رفتن یا همکاری با انسانها استفاده میشود. برای مثال، یک بازوی رباتیک میتواند یاد بگیرد که چگونه اشیای مختلف را با شکلها و وزنهای متفاوت بلند کند، بدون اینکه برای هر شی به طور جداگانه برنامهریزی شود.
مدیریت منابع و زمانبندی
یادگیری تقویتی در بهینهسازی زمانبندی کاربرد دارد، مانند کنترل چراغهای راهنمایی برای کاهش ترافیک یا مدیریت منابع در کارخانهها. این روش میتواند جایگزین روشهای سنتی مانند الگوریتمهای تکاملی شود و راهحلهای کارآمدتری ارائه دهد.
کالیبراسیون سیستمها
در صنایعی مانند خودروسازی، یادگیری تقویتی برای کالیبراسیون خودکار پارامترهای پیچیده، مانند واحدهای کنترل الکترونیکی (ECU)، استفاده میشود. این روش زمان و هزینههای کالیبراسیون دستی را کاهش میدهد.
بازیها و سرگرمی
یادگیری تقویتی در توسعه هوش مصنوعی برای بازیهای پیچیده مانند شطرنج، گو و بازیهای ویدیویی موفقیتهای بزرگی کسب کرده است. این الگوریتمها میتوانند استراتژیهای پیشرفتهای را یاد بگیرند که حتی میتواند بازیکنان حرفهای را شکست دهند.
چالشهای یادگیری تقویتی
با وجود مزایای متعدد، یادگیری تقویتی با چالشهایی همراه است. یکی از بزرگترین چالشها، نیاز به تعداد زیادی تعامل با محیط است. برای مثال، AlphaGo برای رسیدن به عملکرد بهینه، میلیونها بازی را شبیهسازی کرد که معادل هزاران سال تجربه انسانی بود. این موضوع باعث میشود که آموزش در برخی کاربردها زمانبر و پرهزینه باشد.
چالش دیگر، طراحی سیگنال پاداش مناسب است. اگر پاداش به درستی تعریف نشود، عامل ممکن است رفتارهای نامطلوبی را یاد بگیرد. برای مثال، در یک سیستم رانندگی خودکار، اگر پاداش فقط بر اساس سرعت تعریف شود، عامل ممکن است ایمنی را نادیده بگیرد. تنظیم دقیق پاداش نیازمند درک عمیق از مسئله و چندین مرحله آزمایش است.
پیچیدگی محاسباتی نیز یک مانع است. مسائل پیچیده نیازمند شبکههای عصبی پیشرفته و منابع محاسباتی قوی مانند GPUها هستند. علاوه بر این، فرآیند آموزش ممکن است ناپایدار باشد و به تنظیم دقیق پارامترهای الگوریتم (Hyperparameters) نیاز داشته باشد.
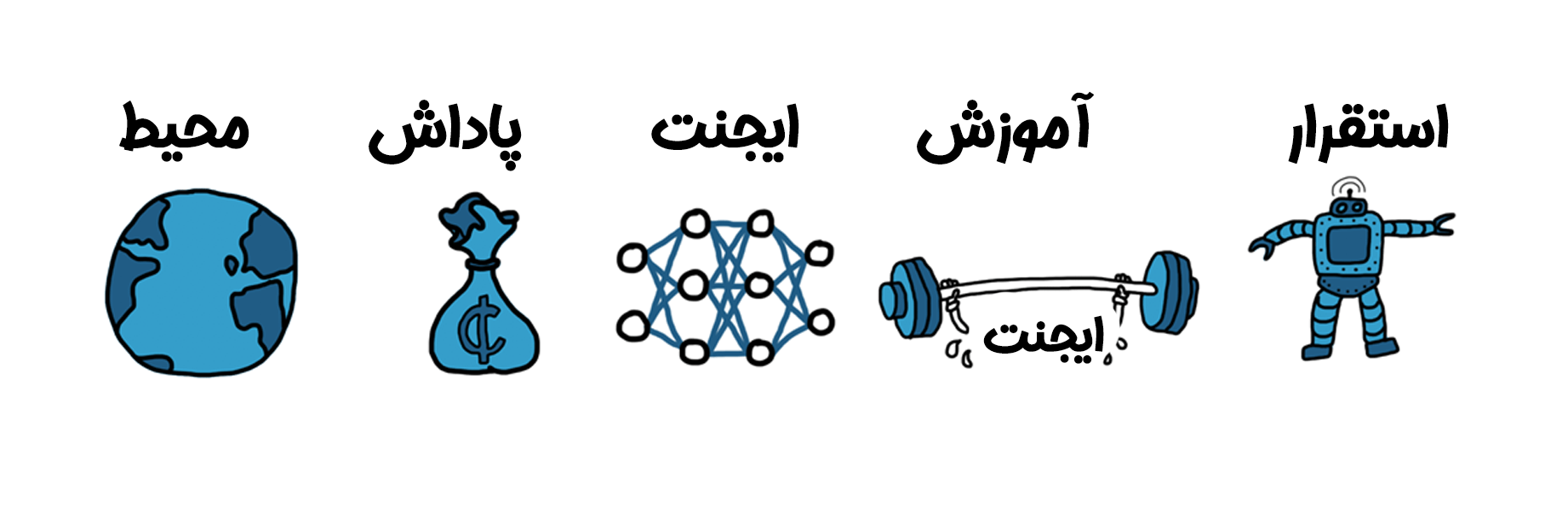
مراحل پیادهسازی یادگیری تقویتی
پیادهسازی یک پروژه یادگیری تقویتی شامل مراحل زیر است:
۱. ایجاد محیط
اولین قدم، تعریف محیطی است که عامل در آن عمل میکند. این محیط میتواند یک شبیهسازی (مانند یک مدل در Simulink) یا یک سیستم واقعی باشد. محیط باید شامل تمام دینامیکها و قوانین مربوطه باشد، مانند قوانین فیزیکی در رباتیک یا قوانین یک بازی.
۲. تعریف پاداش
سیگنال پاداش باید به گونهای طراحی شود که عملکرد عامل را به درستی ارزیابی کند. برای مثال، در یک سیستم پارک خودکار، پاداش میتواند بر اساس فاصله خودرو از محل پارک یا عدم برخورد با موانع تعریف شود. طراحی پاداش یکی از حساسترین مراحل است و ممکن است نیاز به چندین بار اصلاح داشته باشد.
۳. ایجاد ایجنت
ایجنت شامل یک سیاست و یک الگوریتم یادگیری است. سیاست میتواند با استفاده از شبکههای عصبی، جداول جستجو یا روشهای دیگر مدلسازی شود. الگوریتمهای یادگیری تقویتی مانند (DQN: Deep Q-Network)، (DDPG: Deep Deterministic Policy Gradient) یا (PPO: Proximal Policy OptimizationPPO) برای تنظیم سیاست استفاده میشوند.
۴. آموزش و اعتبارسنجی
پس از تنظیم گزینههای آموزش (مانند معیارهای توقف)، عامل آموزش داده میشود. این فرآیند ممکن است بسته به پیچیدگی مسئله، از چند دقیقه تا چند روز طول بکشد. پس از آموزش، سیاست باید اعتبارسنجی شود تا از عملکرد صحیح آن اطمینان حاصل شود. اگر نتایج مطلوب نبود، ممکن است نیاز به اصلاح پاداش، معماری سیاست یا تنظیمات الگوریتم باشد.
۵. استقرار
پس از آموزش، سیاست بهینهشده میتواند در سیستمهای واقعی یا شبیهسازیشده مستقر شود. برای مثال، در یک خودرو خودران، سیاست آموزشدیده میتواند به صورت کد C++ یا CUDA تولید شده و روی سختافزار خودرو اجرا شود.
ابزارهای یادگیری تقویتی
ابزارهای متعددی برای پیادهسازی یادگیری تقویتی وجود دارند که کار را سادهتر میکنند:
MATLAB و Simulink
MATLAB با ابزار Reinforcement Learning Toolbox امکان تعریف محیط، پاداش و سیاست را فراهم میکند. این ابزار برای کاربردهای مهندسی مانند رباتیک و سیستمهای کنترل بسیار مناسب است. همچنین، با استفاده از Parallel Computing Toolbox میتوان آموزش را با GPUها و خوشههای محاسباتی تسریع کرد.
TensorFlow و PyTorch
این کتابخانههای متنباز پایتون برای پیادهسازی الگوریتمهای یادگیری تقویتی عمیق بسیار محبوب هستند. آنها انعطافپذیری بالایی برای طراحی شبکههای عصبی پیچیده ارائه میدهند.
OpenAI Gym
این پلتفرم متنباز محیطهای استانداردی برای آزمایش الگوریتمهای یادگیری تقویتی مانند بازیهای کلاسیک یا شبیهسازیهای رباتیک فراهم میکند.
جمعبندی
یادگیری تقویتی به عنوان یکی از قدرتمندترین روشهای مبتنی بر هوش مصنوعی، توانایی حل مسائل پیچیدهای را دارد که حل آنها با روشهای سنتی دشوار است. این فناوری از رانندگی خودکار و رباتیک گرفته تا بهینهسازی زمانبندی و کالیبراسیون سیستمها، در حال تحول صنایع مختلف است.
منبع : mathworks




