

یادگیری عمیق (Deep Learning) یکی از پیشرفتهترین شاخههای یادگیری ماشینی است که امکان استخراج خودکار ویژگیها و الگوهای پیچیده از دادهها را فراهم میکند. این فناوری بر پایه شبکههای عصبی مصنوعی با لایههای متعدد بنا شده و توانایی پردازش دادههای پیچیده و غیرخطی را دارد. به دلیل قابلیت یادگیری خودکار ویژگیها، یادگیری عمیق بهطور گسترده در حوزههایی مانند شناسایی تصویر، ترجمه زبان، پردازش صوت و خودروهای خودران استفاده میشود.
پایهگذاری یادگیری عمیق
پایه و اساس یادگیری عمیق بر مبنای شبکههای عصبی مصنوعی است که از ساختار مغز انسان الهام گرفتهاند. این شبکهها شامل نودها یا نورونهایی هستند که در لایههای مختلف به هم متصل شدهاند و دادهها را پردازش میکنند. هر لایه وظیفه خاصی در تحلیل دادهها دارد. لایههای ابتدایی ویژگیهای سادهای مانند خطوط و لبهها را شناسایی میکنند، در حالی که لایههای عمیقتر میتوانند آبجکت پیچیدهتر مانند چهرهها را تشخیص دهند. این فرآیند که با عنوان یادگیری ویژگیها شناخته میشود، دقت بالای این فناوری را در تحلیل دادههای تصویری و صوتی توجیه میکند.
تفاوت یادگیری عمیق و یادگیری ماشینی سنتی
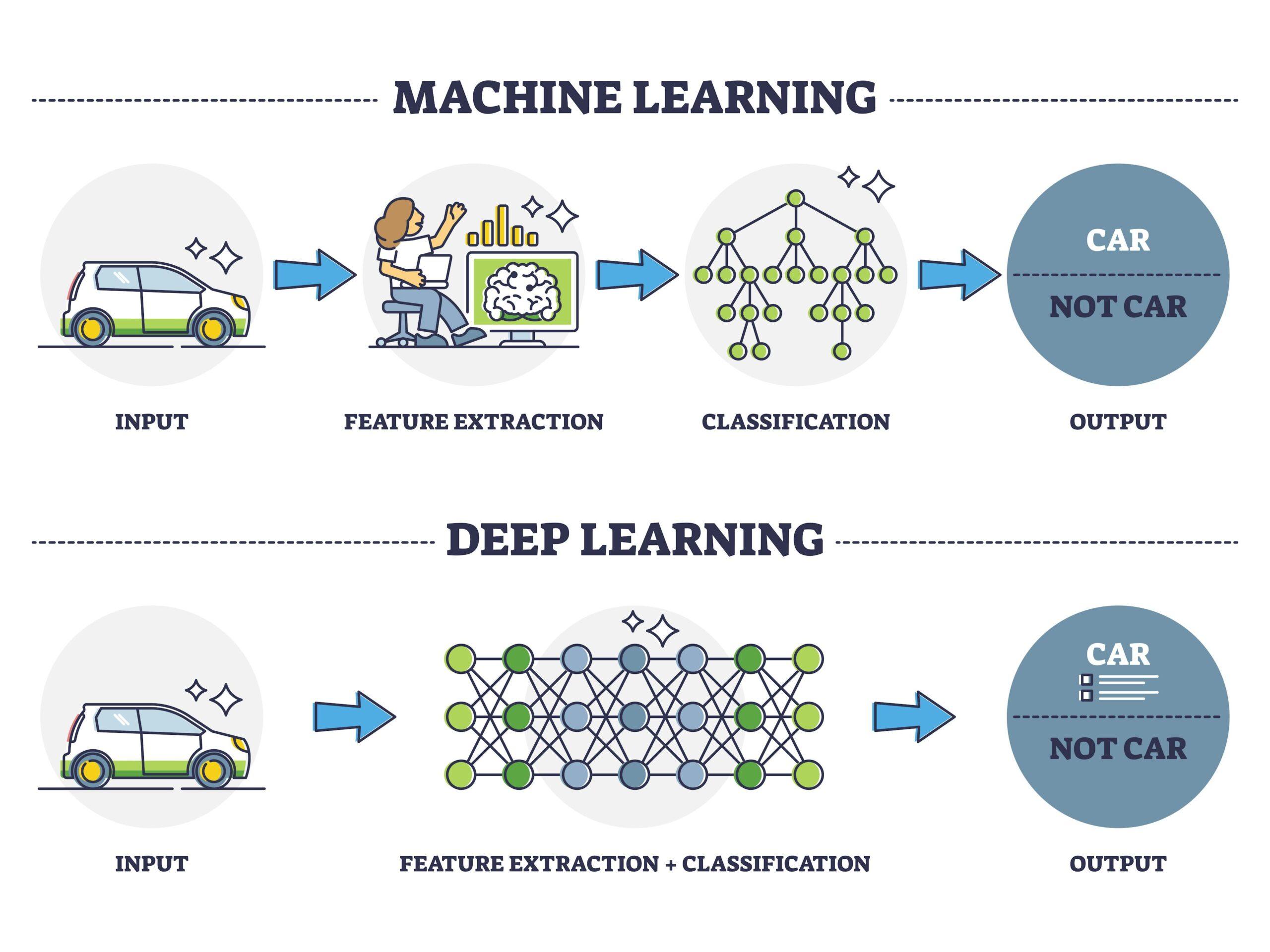
در یادگیری ماشینی سنتی، متخصصان معمولاً ویژگیها و الگوهای دادهها را بهصورت دستی شناسایی و استخراج میکنند. در مقابل، یادگیری عمیق این فرایند را خودکار کرده و مدلها مستقیماً ویژگیهای مرتبط را از دادهها استخراج میکنند. این تفاوت کلیدی باعث میشود مدلهای یادگیری عمیق دادههای پیچیده و حجیم را با دقت و کارایی بیشتری تحلیل کنند. این روش به سیستمها امکان میدهد الگوهای غیر خطی و پیچیده را بدون نیاز به مداخله انسانی شناسایی کنند.
معماری شبکههای عصبی
شبکههای عصبی مصنوعی که پایه اصلی یادگیری عمیق هستند، از سه نوع لایه تشکیل شدهاند. لایه ورودی که دادهها از طریق آن وارد شبکه میشوند و معمولاً تعداد نودهای آن برابر با تعداد ویژگیهای داده ورودی است. لایههای مخفی که وظیفه پردازش دادهها و استخراج ویژگیها را بر عهده دارند. هرچه تعداد این لایهها بیشتر باشد، شبکه قادر به شناسایی الگوهای پیچیدهتری خواهد بود. لایه خروجی نیز نتیجه نهایی پردازش شبکه را ارائه میدهد و در مسائل دستهبندی، خروجی میتواند احتمال تعلق داده به یک کلاس خاص باشد. هر نورون در این لایهها با استفاده از وزنها و بایاسها سیگنالهای ورودی را پردازش کرده و به لایه بعدی منتقل میکند. این وزنها طی فرآیند آموزش، بهینهسازی میشوند تا دقت شبکه افزایش یابد.
انواع مدلهای یادگیری عمیق
یادگیری عمیق شامل مدلهای مختلفی است که هرکدام برای نوع خاصی از دادهها و وظایف طراحی شدهاند. شبکههای عصبی پیچشی (CNN) عمدتاً برای تحلیل دادههای تصویری و ویدئویی بهکار میروند. این مدلها میتوانند ویژگیهای بصری مانند لبهها و بافتها را شناسایی کنند و در سیستمهای تشخیص تصویر و تحلیل تصاویر پزشکی بسیار موفق عمل کردهاند. شبکههای عصبی بازگشتی (RNN) برای دادههای ترتیبی مانند متن و صوت طراحی شدهاند. این شبکهها با توانایی حفظ حافظه کوتاهمدت، برای وظایفی مانند ترجمه زبان و تحلیل سریهای زمانی بسیار مؤثر هستند. مدلهای مبتنی بر مکانیزم توجه مانند ترنسفورمرها نیز در پردازش زبان طبیعی (NLP) کاربرد دارند و در مدلهای پیشرفتهای مانند BERT و GPT مورد استفاده قرار گرفتهاند.
کاربردهای این فناوری
در حوزه بینایی ماشین، مدلهای یادگیری برای تشخیص چهره، شناسایی اشیاء و تحلیل تصاویر پزشکی کاربرد دارند. مدلهای CNN در تشخیص بیماریهای از تصاویر رادیولوژی مانند سرطان عملکرد بسیار موفقی داشتهاند. خودروهای خودران نیز با استفاده از یادگیری عمیق قادر به شناسایی محیط اطراف، تشخیص موانع و اتخاذ تصمیمهای حرکتی هستند. در سیستمهای پیشنهاددهنده مانند نتفلیکس و آمازون، یادگیری عمیق رفتار کاربر را تحلیل کرده و بر اساس علایق او محتوای مناسب را پیشنهاد میدهد. همچنین این فناوری در شناسایی تقلبهای بانکی و امنیت سایبری با تحلیل رفتارهای مشکوک و الگوهای غیرعادی مؤثر بوده است.
چالشها و محدودیتهای یادگیری عمیق
این فناوری با وجود پیشرفتهای چشمگیر، با چالشهایی نیز روبهرو است. نیاز به کلاندادهها یکی از مهمترین موانع این فناوری محسوب میشود. مدلهای یادگیری عمیق برای آموزش مؤثر نیاز به مجموعه دادههای حجیم دارند تا بتوانند الگوهای دقیقتری را شناسایی کنند. علاوه بر این، منابع محاسباتی بالایی مانند پردازندههای گرافیکی (GPU) برای پردازش حجم بالای دادهها و آموزش مدلها مورد نیاز است که میتواند هزینهبر باشد. پیچیدگی معماری شبکههای عمیق نیز باعث میشود تنظیم و بهینهسازی آنها زمانبر و نیازمند تخصص بالا باشد.
منبع: IBM




